Det er nok de færreste, der går og tænker over at for bare 50 år siden, eksisterede CT-skannere slet ikke, og mulighederne for at se ind i kroppen uden at åbne op, var ganske begrænsede. Man kunne tage røntgenbilleder, men den slags billeder giver slet ikke den samme detaljegrad som CT. I dag bruges røntgen primært til at observere knoglestrukturer og sygdom i blødt væv i kroppen.
Røntgenstråler har været kendt siden slutningen af 1800-tallet, hvor de blev opdaget og navngivet efter den tyske fysiker Willhelm Röntgen, der var den første til at systematisk studere strålerne.
Allerede for omkring 100 år siden i 1917 lagde den østrigske matematiker Johann Radon det matematiske grundlag for CT-skanning, som vi kender det i dag. Han studerede projektioner, det at tage et objekt og afbillede i en lavere dimension, og mulighederne for at rekonstruere objektet, hvis man kender nok afbilledeninger af det. For et simpelt eksempel forestil dig en figur i LEGO, og hvor mange billeder fra forskellige vinkler du ville have brug for, hvis du skulle bygge den igen kun ud fra billederne.
Der skulle dog gå lang tid før CT-skannerne kom. Først over 50 år senere i 1971, blev den første praktiske brugbare CT-skanner markedsført. Det var Allan McLeod Cormack og Godfrey Hounsfields fælles indsats op gennem 50'erne og 60'erne, der gjorde maskinen til virkelighed og de modtog for deres arbejde Nobelprisen i Medicin i 1979.
Sidenhen er CT-skannere blevet langt mere sofistikerede, som du også kan se herunder. Hounsfields prototype og den første serie af CT-skannere skannede langs parallelle linier, mens nyere modeller skanner langs en vifte af linier udspringende fra det samme punkt. Det har en række tekniske fordele, som vi ikke vil gå i detaljer med her. Den teori vi senere vil gennemgå beskæftiger sig med metoden med parallelle linier, men kan generalisers til vifte situationen. Det kunne måske være et spændende projekt i sig selv.
Tomografisk rekonstruktion er ikke nogen nem diciplin. Det hører under klassen af problemer, som kaldes inverse problemer, der kan være problematiske at løse af forskellige årsager. For at kunne tale nærmere om dette, er det en god ide af få på plads, hvad der menes med et inverst problem
Inverse problemer
Problemer i matematik kommer så godt som altid på formen:
Givet funktion $ f $ og variablen $ y $, find $ x $ så $ f(x) = y $ er opfyldt.
Nogle gange beder vi om alle $ x $ der opfylder ligningen. Eksempelvis:
(a) Hvis $ f(x) = x^2 + x + 1 $ og $ y = 0 $ er problemet præcis at løse andengrandsligningen.
(b) Hvis
$$ f(x(t)) = \frac{dx}{dt}(t) + x(t) $$
og $ y(t) = t^2 $ er problemet at løse differentialligningen.
I inverse problemer er det som sådan ikke anderledes. Vi har en forward afbildning $ f $, typisk gennem matematisk modellering af et fysisk fænomen. Denne beskriver, hvordan den ukendte størrelse $ x $ producerer den kendte størrelse $ y $. Spørgsmålet er nu som før: Givet $ y $, hvad var $ x $?
Så hvad er anderledes? I problemerne (a) og (b) findes der løsningsformler, $ f^{-1} $ findes i en eller anden forstand. Men et inverst problem har som oftest ikke en løsningsformel, og selv hvis $ f^{-1} $ eksisterer er den ustabil på en sådan måde at en lille ændring i $ y $ fx $ y+\delta $, kan give gevaldige udsving i det resulterende $ x $. Det er problematisk, da vi oftest er interesserede i naturfænomer og dermed indsamlede data. Data kan vi kun opnå til en vis præcision og vi har derfor i praksis aldrig præcis $ y $, men derimod $ y + \delta $.
Som om problemet ikke var stort nok, er det muligt at $ y + \delta $ slet ikke findes i værdimængden for $ f $.
Tomografi
I vores problem viste Johann Radon allerede for 100 år siden at der findes en invers til vores forward afbildning $ f $. Desværre er den sensitiv overfor støj (problemet med at have $ y+\delta $ i stedet for $ y $) og så den skal rent teknisk bruge uendeligt mange målinger, hvilket man naturligvis ikke kan lave i praksis. Computer implmenterede varianter af Radons inversionsformel er dog stadig den mest anvendte teknik i kommercielle skannere i dag, men den kræver skanninger fra mange vinkler[2].
For at kunne gøre noget som helt, må vi dog have forward afbildningen. Denne er Radontransformationen. I de følgende afsnit vil vi gennemgå matematikken, der skal til for at forstå Radontransformationen.
Fysikken
For at kunne snakke meget mere om vores problem og dermed matematikken, må vi have lidt bedre styr på fysikken der spiller ind i vores forward problem. Et datum (en måling) i en CT-skanning foretages ved sending af en røntgensstråle gennem objektet i skanneren. På den anden side af objektet er placeret en detektor, hvor strålen ender i. Detektoren måler intensisteten af strålen, når den passerer ud af objektet, og man sammenligner denne med intensiteten, man ville have observeret, hvis objektet ikke havde været der. For at forstå nærmere, hvordan vi kan bruge dette, skal vi vide noget om hvordan elektromagnetisk stråling opfører sig når det passerer igennem stof.
Lamberts lov
Intensisteten af en stråle beskriver energien i strålen, hvilken er afhængig af mængden af fotoner i strålen.
Absorbtion af en foton, der bevæger sig gennem et absorberede materiale er ikke garanteret, men derimod et spørgsmål om sandsynlighed. Så hvis sandsynligheden for at en foton $ q $ absorberes ved passage gennem et materiale $ M $ er givet ved $ p $, da stiger sandsynligheden naturligvis, hvis vi placerer flere identiske materialer på hinanden følgende langs fotonens bane. Mere specifikt bliver sandsyndligheden for absorbtion bliver $ 1 - (1-p)^n $ for $ n $ kopier af $ M $ i rækkefølge. En stråle indeholder dog så mange fotoner at det stokastisk element udgår til fordel for middelværdien.
Placerer vi et tyndt stykke materiale med tykkelse $ dx $ langs banen af en stråle med ingående intensitet $ I $ vil den udgående intensitet være givet ved $ I + dI $, hvor $ dI $ er itensitetsfaldet hen over materialet; læg mærke til at $ dI $ er negativ. Intensitetsfaldet er så givet ved[7]
\begin{equation} \label{eq:lambert_law}
dI = -\mu I dx.
\end{equation}
Dette er Lamberts lov efter Johann Heinrich Lambert i 1760; på trods af at loven blev opdagelet af Pierre Bouguer, der publiserede den i 1729, hvorfra Lambert citerede den.
$ \mu $ kaldes absorbtionskoefficienten eller dæmpningskoefficienten, og for opløsninger af stof i væske, gælder det at $ \mu = \ln(10)\epsilon C $, hvor $ C $ er koncentrationen af stoffet og $ \epsilon $ kaldes den molære ekstinktionskoefficient. Denne sammenhæng er Beers lov efter August Beer i 1852.
Hvis vi anser det tynde stykke materiale, som et slice af et større objekt, kan vi ved separation af variable i \eqref{eq:lambert_law} integrere over hele strålens bane
\begin{equation}
\int_{I_0}^I \frac{dI}{I} = -\int_0^x \mu\,dx \quad \Longleftrightarrow \quad I(x) = I_0e^{-\int_0^x \mu\,dx},
\end{equation}
hvor $ I_0 $ er begyndelsesintensiteten. Hvis $ \mu $ er konstant langs strålen simplicerer udtrykket til $ I(x) = I_0\exp(-\mu x) $. Hvis materialet vi sendte strålen igennem havde længden $ L $ og vi antager af luften har $ \mu = 0 $, kan vi ud fra den målte $ I $ og kendte $ I_0 $ bestemme $ \mu = -L^{-1}\ln(I/I_0) $.
Forward problemet
Generelt er vi ikke så heldige at $ \mu $ er konstant, men derimod vil $ \mu = \mu(x) $ variere med $ x $. Det er derfor man i en CT-skanning laver masser af målinger langs en myriade af forskellige baner gennem objektet. Vi kalder valget af baner for strålerne for skanningens geometri. Kalder vi den $ i $'te bane i vores geometri $ \ell_i $, er vores forward problem nu som følger: Givet $ \mu(x) $ kan vi beregne vores data $ I_i $ ved
\begin{equation} \label{eq:fwd-problem}
I_i = I_0 e^{-\int_{\ell_i} \mu(x)\,ds},
\end{equation}
hvor $ \int_\ell \mu(x)\,ds $ er integralet langs banen $ \ell_i $. Det inverse problem er (naturligvis) det modsatte: Givet vores data $ (I_1,I_2,I_3,...) $ bestem $ \mu(x) $ så \eqref{eq:fwd-problem} holder for alle valg af $ i $.
I praksis vil vi, som beskrevet her, have et endeligt sæt udvalgte baner $ (\ell_1,\ell_2,\dots,\ell_N) $ vi bestråler langs, hvilket giver os en endelig mængde data $ (I_1,I_2,\dots,I_N) $ at arbejde med. Men for det teoretiske scenarie vi vil se på videre, antager vi, at vi kan måle langs alle tænkelige baner (alle rette linier) gennem objektet, hvilket giver os uendeligt mange data i form af profilkurver $ p_\theta(\rho) $, der samler alle data hørende til baner med samme retning $ \theta $.
Koordinater og vektorrum
Koordinater
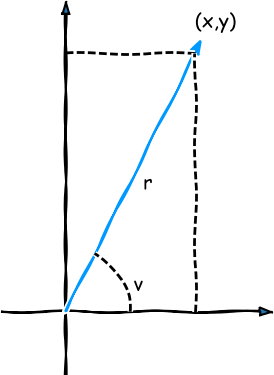
Polære og kartesiske koordinater. Her er vinklen '$ \theta $' skrevet som 'v'.
En vektor er en abstrakt størrelse i matematik og som det meste andet matematik er det mange måder at repræsentere den på. Vi siger ofte at en vektor er en størrelse og en retning og benytter pile i et koordinatsystem til at repræsentere dette. Specielt har en vektor ikke en position, så hvis vi flytter en pil rundt i koordinatsystemet (bevarende længden og retningen den pejer i) er der tale om den samme vektor. På den måde adskiller vektorer sig fra punkter i koordinatsystemet, på trods af at vi ofte skriver punkter og vektorer på samme måde, som talpar $ (x,y) $ i det 2-dimensionelle tilfælde.
Vælger vi at afsætte en vektor ud fra origo har vi specielt at vektoren $ (x,y) $ pejer på punktet $ (x,y) $ og vi kalder den en stedvektor. Vi kan således i mange situationer anskue stedvektorer og punkter som ens og skifte frem og tilbage mellem dem efter behov. Siden en vektor ikke som udgangspunkt er knyttet til et bestemt sted i et koordinatsystem, kan vi anskue alle vektorer som stedvektorer, hvis situationen kalder for det.
For stedvektoren $ (x,y) $ angiver koordinaterne $ x $ og $ y $, hvor lang vektoren er projekteret ned på $ x $-aksen henholdvis $ y $-aksen. Men dette er blot en måde at repræsentere en vektor på, vi kalder dette de kartesiske koordinater.
En vektors (hhv. et punkts) kartesiske koordinater er repræsentationen $ (x,y) $, hvor $ x $ er længden langs $ x $-aksen, og $ y $ er langden langs $ y $-aksen.
De kartesiske koordinater er nok de mest velkendte og måske derfor også de mest naturlige for mange. Men til tider kan det være en fordel at benytte andre måder at repræsentere vektorer (og punkter) på. Vi husker, at en vektor ofte beskrives som havende en størrelse og en retning. Dette giver os et hint til en anden måde at skrive en vektor på.
En vektors (hhv. et punkts) polære koordinater er repræsentationen $ (r,\theta) $, hvor $ r $ er længden af vektoren (hhv. afstanden fra origo til punktet), og $ \theta $ er vinklen mellem $ x $-aksen og vektoren målt positivt mod uret rundt om origo.
Det er ganske nemt at bestemme en vektors kartesiske koordinater ud fra de polære, hvis man tænker på på vektoren som hypotenusen i en retvinklet trekant, hvor en af siderne ligger langs $ x $-aksen (se figur 4). I så fald giver en simpel trigonometrisk betragtning os følgende resultat.
Hvis en vektor (hhv. et punkt) har de polære koordinater $ (r,\theta) $, da er de kartesiske koordinater for vektoren (hhv. punktet) $ (x,y) $, hvor
\begin{equation}
x = r\cos\theta \qquad \text{og} \qquad y = r\sin\theta.
\end{equation}
At gå den anden vej er til tider en anelse mere kompliceret.
Hvor en vektor (hhv. et punkt) har de kartesiske koordinater $ (x,y) $, da er de polære koordinater for vektoren (hhv. punktet) $ (r,\theta) $, hvor
\begin{equation}
r = \sqrt{x^2 + y^2} \qquad \text{og} \qquad \tan\theta = \frac{y}{x}.
\end{equation}
Vinklen $ \theta $ kan regnes direkte med formlen
\begin{equation}
\theta = \tan^{-1}\left(\frac{y}{x}\right) + \chi_{x<0}\pi,
\end{equation}
hvor $ \chi_{x<0} $ er en indikatorfunktion; dvs. $ \chi_{x<0}=1 $, hvis $ x < 0 $ og ellers er den 0.
Vektoren med kartesiske koordinater $ (4,3) $ har de polære koordinater $ r = \sqrt{4^2 + 3^2} = 5 $ og $ \theta = \tan^{-1}(3/4) \approx 0.6435 $ radianer, hvilket svarer til ca. $ 36.87^\circ $, siden radianer og grader har en faktor $ 180/\pi $ til forskel.
Vektorrum
Mængden af alle vektorer på formen $ (x,y) $ betegnes $ \mathbb{R}^2 $. Mere generelt betegner vi mængden af alle vektorer på formen $ (x_1,x_2,\dots,x_n) $ med symbolet $ \mathbb{R}^n $. Hvis en mængde af vektorer har en vis struktur, kaldes den et vektorrum.
En mængde $ V $ er et vektorrum, hvis $ V $ opfylder
\begin{align}
\mathbf{v}_1, \mathbf{v}_2 \in V \qquad &\text{medfører at} \qquad \mathbf{v}_1 + \mathbf{v}_2 \in V, \label{eq:VC1}\\
a \in \mathbb{R}, \mathbf{v} \in V \qquad &\text{medfører at} \qquad a\mathbf{v} \in V. \label{eq:VC2}
\end{align}
Egentlig kræves en række yderligere krav til et vektorrum, men de rum vi vil se her opfylder naturligt de resterende krav. Se evt. mere i [10].
Vi husker at vektorer kan lægges sammen ved at addere dem elementvis, så for vektorer $ \mathbf{x} = (x_1,\dots,x_n) $ og $ \mathbf{y} = (y_1,\dots,y_n) $ i $ \mathbb{R}^n $ gælder det at
$$ \mathbf{z} = \mathbf{x} + \mathbf{y} = (x_1+y_1,\dots,x_n+y_n). $$
Tydeligvis har $ \mathbf{z} $ også præcis $ n $ elementer og er derfor en vektor i $ \mathbb{R}^n $.
Vi husker ligeledes, at en vektor kan skaleres med en skalar ved at gange den på elementvis. Hvis $ a $ er et reelt tal og $ \mathbf{x} $ er en vilkårlig $ \mathbb{R}^n $-vektor som før
$$ \mathbf{z} = a\mathbf{x} = (ax_1,\dots,ax_n). $$
Igen er $ \mathbf{z} $ en vektor med $ n $ elementer. Betingelser \eqref{eq:VC1}-\eqref{eq:VC2} er altså opfyldt og $ \mathbb{R}^n $ er et vektorrum.
Resultatet at $ \mathbb{R}^n $ er et vektorrum, er måske ikke overraskende, men der findes interessante vektorrum af mere speciel karakter. Lad fx $ V $ og $ W $ være to vilkårlige vektorrum, og $ C(V,W) $ være mængden af kontinuerte funktioner fra $ V $ ind i $ W $. Så er $ C(V,W) $ et vektorrum. Det ser måske intimiderende ud, men hvis vi fx vælger $ V = W = \mathbb{R} $, får vi, at $ C(\mathbb{R},\mathbb{R}) $, hvilket er helt normale kontinuerte funktioner som man kender dem, er et vektorrum. Vi vil vende tilbage til at tale mere om funktioner senere.
Funktioner og parameterisering
Funktioner
En funktion er en matematisk operation, der tager et input $ x $ og producerer et output $ y $. Ofte skriver vi $ f : X \to Y $ for at indikere at funktionen $ f $ går fra mængden $ X $ og afbilleder ind i mængden $ Y $. Værdimængden af en funktion er en del af mængden $ Y $ og definitionsmængden er $ X $ (eller i specielle tilfælde en del af $ X $).
Funktionen $ \sqrt{\cdot} : \mathbb{R}_0^+ \to \mathbb{R} $ går fra de ikke-negative reelle tal, $ \mathbb{R}_0^+ $, ind i de reelle tal, $ \mathbb{R}$.
Vi kan komme med mange velkendte eksempler på funktioner på formen $ f : \mathbb{R} \to \mathbb{R} $, fx polynomier af grad $ n $
eller den velkendte eksponential funktion $ e^x $. Men der er ikke noget der stopper os fra at vælge mere eksotiske mængder i $ X $'s sted, fx $ \mathbb{R}^2 $, $\mathbb{R}^3 $, eller mere generelt $ \mathbb{R}^n $. Vi vil videre holde os til $ \mathbb{R}^2 $, men princippet er det samme for de andre.
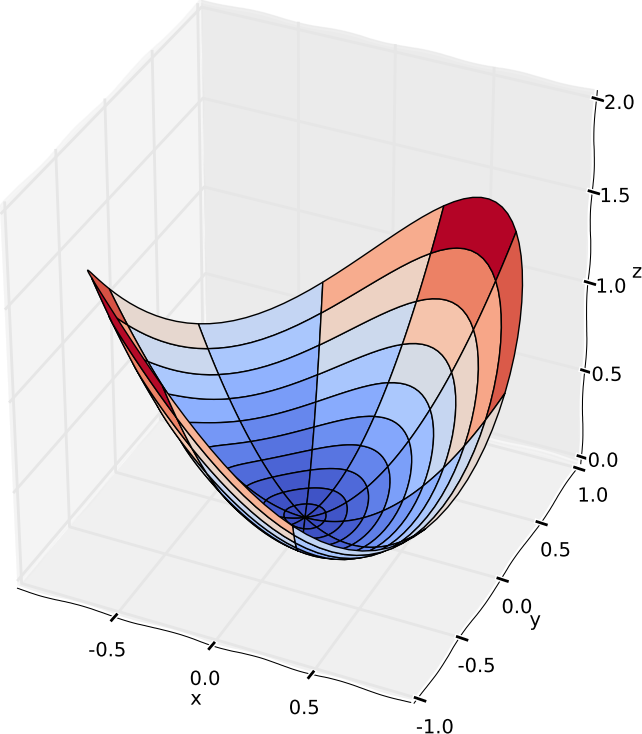
Hvis $ f : \mathbb{R}^2 \to \mathbb{R} $ er vores funktion, tager vi altså en værdi $ (x,y) \in \mathbb{R}^2 $ og producerer noget $ z \in \mathbb{R} $. Et simpelt eksempel kunne være et polynomium i to variable
$$ f(x,y) = x^2 + xy + y^2. $$
Det praktiske med $ \mathbb{R}^2 $ fremfor $ \mathbb{R}^n $, hvor $ n \geq 3 $, er, at vi stadig er i stand til at afbillede funktionen, som vi plejer. I stedet for at grafen er en kurve i $xy$-planen, er grafen nu blot en flade i $ xyz $-rummet. Ligesom $ y = f(x) $ afsættes på $ y $-aksen i $ xy $-planen, kan vi nu afsætte $ z = f(x,y) $ på $ z $-aksen i $ xyz $-rummet. Se figur 5 for en afbilledning af polynomiet.
Det er til tider praktisk at have en kortere notation, og det er også tilfældet her. Hvis vi benytter notationen $ \mathbf{v} = (x,y) $ fra tidligere, forstår vi at $ f(\mathbf{v}) = f(x,y) $. Denne notation har flere fordele, som vi ikke kommer ind på i denne omgang, men vil for os være praktisk når vi sammensætter en funktion af to variable med en parameterisering, hvilket vi kommer ind på snart.
Operatorer
Vi vil benytte lejligheden til at nævne at for $ f:X \to Y $, hvis mængderne $ X $ og $ Y $ er vektorrum, kalder vi til tider $ f $ for en operator. For kort at vende tilbage til funktionsvektorrummet $ C(\mathbb{R}, \mathbb{R}) $, som vi nævnte i slutningen af afsnittet om vektorrum. Vi kan ved hjælp af integration og en kontinuert funktion $ k : \mathbb{R}^2 \to \mathbb{R} $ lave en operator, $ K : C(\mathbb{R},\mathbb{R}) \to C(\mathbb{R},\mathbb{R}) $,
$$ g(x) = (Kf)(x) = \int_a^b k(x,y)f(y)\,dy, $$
hvor $ a $ og $ b $ på forhånd er valgte. En funktion $ k(x,y) $, der indgår i integralet som herover kaldes en kerne eller integrationskerne.
Hvorfor giver dette mening? Hver gang vi vælger et $ x = x_0 $, så har vi blot en bestemt integrale $ \int_a^b h(y)\,dy $, hvor $ h(y) $ er funktionen $ k(x_0,y)f(y) $. Vi husker at sådan et integrale blot producerer et tal. Så til hver $ x $-værdi får vi et tal. Det er sådan en funktion virker, så vi kalder denne funktion for $ g(x) $.
Hvis vi vælger $ a = -1 $, $ b = 1 $, $ k(x,y) = x-y $ og $ f(x) = x^2 $, da har vi
\begin{align*}
(Kf)(x) &= \int_{-1}^1 k(x,y)f(y)\,dy = \int_{-1}^1 (x-y)y^2\,dy \\
&= \int_{-1}^1 xy^2 - y^3\,dy = \left[\frac{1}{3}xy^{3} - \frac{1}{4}y^4\right]_{y=-1}^{y=1} \\
&= \frac{1}{3}x - \frac{1}{4} +\frac{1}{3}x +\frac{1}{4} = \frac{2}{3}x.
\end{align*}
Så $ g(x) = (Kf)(x) = \frac{2}{3}x $.
Parameterisering
Vi mindes at en funktion til enhver input-værdi $ x $ kun kan tilknyttes en enkelt output-værdi $ y $. Det er derfor, vi typisk vælger kvadratroden som den positive af de to rødder, og grunden til at grafen for en funktion aldrig løber tilbage over (eller under) sig selv. Men det virker lidt begrænsende, ikke sandt? Hvad nu hvis vi havde lyst til at beskrive en ganske almindelig krudsedulle som i figur 6? Her kommer parameterisering ind i billedet.
Lad os først vende tilbage til den generelle funktion $ f : X \to Y $, vi havde fat i tidligere. Før valgte vi $ X = \mathbb{R}^2 $ og $ Y = \mathbb{R} $, men hvad nu hvis vi gjorde det omvendte? $ X = \mathbb{R} $ og $ Y = \mathbb{R}^2 $. Så vil der tilenhver input-værdi $ x $ være to outputværdier $ (y_1,y_2) $. Af årsager, der gerne skulle blive klare om et øjeblik, vil vi i stedet kalde inputtet $ t $ og outputtet $ (x,y) $.
Hver $ t $-værdi giver os nu et punkt i $ xy $-planen, og ved at variere $ t $ kan vi forme kurver. Vi beskriver simpelthen separat kurvens bevægelse på $ x $-aksen med funktionen $ x(t) $ og på $ y $-aksen med funktionen $ y(t) $. Således, hvis kurven krydser over sig selv, er der blot tale om forskellige $ t $-værider der afbilleder til samme punkt.
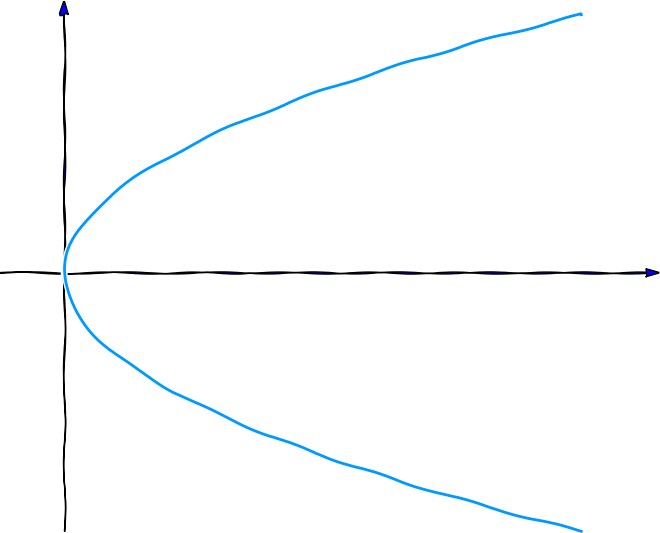
Kvadratrodsfunktionen er $ y = \sqrt{x} $ og gennemløber derfor punkterne $ (x,\sqrt{x}) $ hvor $ x \geq 0 $. Men det er de samme punkter som $ (x^2,x) $, hvor $ x \geq 0 $. Faktisk kan vi få både $ +\sqrt{x} $ og $ -\sqrt{x} $ med $ (x^2,x) $, hvor $ x \in \mathbb{R} $. Se figur 7.
Funktionen $ \mathbf{r}(t) = (x(t),y(t)) $ afbilleder således et interval i $ \mathbb{R} $ til en kurve i $ \mathbb{R}^2 $. Vi kalder også $ \mathbf{r}(t) $ en vektorfunktion, i det hvert input $ t_0 $ resulterer i en vektor; specielt stedvektoren der pejer på punktet $ (x(t_0),y(t_0)) $. Se figur 8 for en illustration af dette.
Dette er alt sammen meget generelt, men vi vil primært være interesserede i at beskrive rette linier. En ret linie beskrives typisk som grafen for funktionen $ f(x) = ax+b $, hvilket giver os en direkte måde at parameterisere linien, nemlig
\begin{align}
\mathbf{r}(t) = (t,at+b). \label{eq:lin-param-naive}
\end{align}
Givet en funktion $ f :\mathbb{R} \to \mathbb{R} $, kan grafen for $ f $ parameterisers som
\begin{equation}
\mathbf{r}(t) = (t,f(t)).
\end{equation}
Parameteriseringen \eqref{eq:lin-param-naive} har dog et mindre problem. Den kan ikke beskrive fundstændig lodrette linier, da de ikke er grafen for en funktion. Lad os undersøge parameteriseringen nærmere,
\begin{align}
\mathbf{r}(t) = \begin{bmatrix} t \\ at+b \end{bmatrix} = \begin{bmatrix} 1 \\ a \end{bmatrix}t + \begin{bmatrix} 0 \\ b \end{bmatrix}.
\end{align}
Parameteriseringen har formen $ \mathbf{v}t + \mathbf{p} $, hvor $ \mathbf{v} $ er en vektor der beskriver retningen, og $ \mathbf{p} $ er et punkt linien gennemløber. En lodret linie ville correspondere til at $ a $ går mod $ \infty $, men $ (1,\infty) $ er ikke en vektor i $ \mathbb{R}^2 $. Men vektoren $ (a^{-1},1) $ har samme retning som $ (1,a) $, og $ (a^{-1},1) \to (0,1) $ når $ a \to \infty $. En lodret linie kan altså beskrives ved at vælge retningsvektoren $ \mathbf{v} $ til $ (0,1) $.
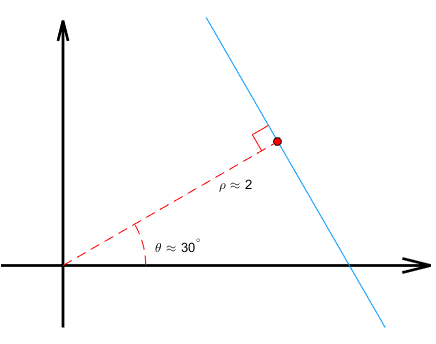
Lemma 12 in action; $ \theta = \pi/6 $.
Vi vil dog være smartere end dette. Når $ a $ ændres varierer længden af $ \mathbf{v} $ nemlig, hvilket vi af visse årsager helst vil være for uden her. Så lad os vælge et $ \theta $ så $ 0 \leq \theta < 2\pi $. Ved at ændre på $ \theta $ inden for de angivne grænser kan vi få vektore $ \mathbf{v} = (\cos\theta,\sin\theta) $ til at peje i præcis den retning vi ønsker.
På samme måde vil vi gerne være lidt smarte omrking, hvordan vi vælger punktet $ \mathbf{p} $, der gennemløbes. Ethvert punkt på vores linie har en afstand til origo, der er minimum $ 0 $. Vi kan altså finde en mindste afstand fra linien til origo; vi kalder den $ \rho $. Hvis man tænker lidt over det, er det klart at den mindste afstand må måles vinkelret ind på linien. Punktet der ligger her må altså være $ \mathbf{p} = \rho \widehat{\mathbf{v}} $.
Den rette linie $ \ell_{\rho,\theta} $ karakteriseret ved vinklen $ \theta $ og den korteste afstand mellem linien og origo, $ \rho $ har parameterfremstillingen
\begin{align}
\mathbf{r}_{\rho,\theta}(t) = \rho\begin{bmatrix} \cos\theta \\ \sin\theta \end{bmatrix} + t\begin{bmatrix} -\sin\theta \\ \cos\theta \end{bmatrix}. \label{eq:lin-param}
\end{align}
For et eksempel, se Figur 9.
Liniens retning kan karakteriseres ved vinklen,
$$ \phi = \theta - \frac{\pi}{2}. $$
Med hensyn til denne bliver parameteriseringen
\begin{align}
\widetilde{\mathbf{r}}_\ell(t) = \rho\begin{bmatrix} -\sin\phi \\ \cos\phi \end{bmatrix} + t\begin{bmatrix} \cos\phi \\ \sin\phi \end{bmatrix}. \label{eq:lin-param-alt}
\end{align}
En linie kan være parameteriseret i to forskellige retninger, og vi ikke kan se forskel på om det var den ene eller den anden retning vi kom fra. Derfor er det klart, at linierne $ \ell $ og $ \ell' $, der er karakteriseret ved henholdsvis $ (\rho, \theta) $ og $ (-\rho, \pi-\theta) $, beskriver den samme linie. Ergo kan vi begrænse $ \theta $ til et interval af længen $ \pi $, fx $ \theta \in [0,\pi) $ og stadig få alle linier med (hvis $ \rho \in \mathbb R $).
Liniens ligning er givet ved $$ n_x(x-x_0) + n_y(y-y_0) = \mathbf{n}(\mathbf{p} - \mathbf{p}_0) = 0, $$ hvor $ \mathbf{n} = (n_x,n_y) $ er en normalvektor til linien, $ \mathbf{p} = (x,y) $ og $ \mathbf{p_0} = (x_0,y_0) $ er et punkt på linien. Benytter vi lemma 12 har vi $ \mathbf{n} = (\cos\theta, \sin\theta) $ og $ \mathbf{p}_0 = \rho(\cos\theta,\sin\theta) $ og dermed
$$ \begin{bmatrix} \cos\theta \\ \sin\theta \end{bmatrix}\left(\begin{bmatrix} x \\ y \end{bmatrix} - \rho\begin{bmatrix} \cos\theta \\ \sin\theta \end{bmatrix}\right) = x\cos\theta + y\sin\theta - \rho = 0 $$
dvs. en alternativ form for liniens ligning er givet ved
\begin{equation}
x\cos\theta + y\sin\theta = \rho.
\end{equation}
Kurveintegraler
For en funktion $ f $ fortæller integralregningens fundamentalsætning os at
\begin{align} \label{eq:int-fund}
\int_a^b f(x)\,dx = F(b)-F(a),
\end{align}
hvor $ F $ er stamfunktionen til $ f $. Integraler over et interval på denne facon er vi gode til at arbejde med. Hvis $ g : \mathbb{R}^2 \to \mathbb{R} $ er en funktion i to variable med $ f(x) = g(x,0) $ så er integralet i \eqref{eq:int-fund} det samme som integralet af $ g $ langs kurven på $ x $-aksen fra $ x=a $ til $ x=b $. Vi vil nu generellisere dette, så vi kan spørge:
Givet en kurve $ \mathcal K $ i $ xy $-planen og en funktion $ g : \mathbb{R}^2 \to \mathbb{R} $, hvad er integralet af $ g $ langs $ \mathcal K $?
Vi skriver integralet af $ g $ langs $ \mathcal K $ som
\begin{align}
\int_\mathcal{K} g(x,y)\,d\mu,
\end{align}
hvilket ser lidt specielt ud, men vi kan tænke lidt på det som et symbol. Hvordan vi regner værdien af integralet ud, kommer vi til.
Lad os først antage, at vi kan beskrive kurven $ \mathcal{K} $ med en parameterfremstilling $ \mathbf{r}(t) = (x(t),y(t)) $, hvor $ t \in I $ for et kendt interval $ I = (a,b) $ og $ x(t) $ og $ y(t) $ er differentiable funktioner. I så fald er $ g $'s værdi på $ \mathcal{K} $ beskrevet ved
\begin{equation}
g(\mathbf{r}(t)) = (g\circ \mathbf{r})(t) = g(x(t),y(t)).
\end{equation}
For et vilkårligt $ m \in \mathbb{N} $ opdeler vi nu intervallet $ I $ uniformt således at
$$ a = t_0 < t_1 < \dots < t_{m-1} < t_m = b, $$
og $ t_i - t_{i-1} = \Delta t = \frac{1}{m} $ uafhængig af $ i $.
Vi kan nu approksimere integralet af $ g $ langs kurven som en Riemann sum
\begin{align}
\int_\mathcal{K} g(x,y)\,d\mu =\lim_{m\to \infty} \sum_{i=0}^{m-1} g(\mathbf{r}(t_i))\Delta s_i = \int_a^b g(\mathbf{r}(t))\,ds, \label{eq:Riemann-sum}
\end{align}
hvor $ \Delta s_i $ er længden af liniestykket fra punktet $ \mathbf{r}(t_i) $ til $ \mathbf{r}(t_{i+1}) $. Dette stykke har længden
\begin{align}
\Delta s_i = \sqrt{\Delta x_i^2 + \Delta y_i^2}, \label{eq:delta-s}
\end{align}
hvor
\begin{align}
\Delta x_i = x(t_i + \Delta t) - x(t_i) = \frac{x(t_i + \Delta t) - x(t_i)}{\Delta t}\Delta t
\end{align}
og analogt for $ \Delta y_i $. Indsætter vi ind i \eqref{eq:delta-s} får vi
\begin{align*}
\frac{\Delta s_i}{\Delta t} = \sqrt{\left(\frac{x(t_i + \Delta t)-x(t_i)}{\Delta t}\right)^2 + \left(\frac{y(t_i+\Delta t)-y(t_i)}{\Delta t}\right)^2}.
\end{align*}
Lader vi $ m \to \infty $ går $ \Delta t \to 0 $ og vi efterlades med
\begin{align}
\frac{ds}{dt} = \sqrt{x'(t)^2 + y'(t)^2} = |\mathbf{r}'(t)|.
\end{align}
Det vil sige \eqref{eq:Riemann-sum} bliver
\begin{align*}
\int_\mathcal{K} g(x,y)\,d\mu = \int_a^b g(\mathbf{r}(t))ds = \int_a^b g(\mathbf{r}(t))|\mathbf{r}'(t)|dt.
\end{align*}
Lad $ g : \mathbb{R}^2 \to \mathbb{R} $ være en kontinuert funktion og $ \mathcal{K} $ en kurve i $ xy $-planen parameteriseret ved $ \mathbf{r}(t) = (x(t),y(t)) $, hvor $ t \in (a,b) $ og $ x(t) $ og $ y(t) $ er differentiable. Så er integralet af $ g $ langs $ \mathcal{K} $
\begin{align}
\int_\mathcal{K} g(x,y)\,d\mu = \int_a^b g(\mathbf{r}(t))|\mathbf{r}'(t)|dt.
\end{align}
Er kurven en ret linie $ \ell $ som beskrevet i lemma 12, har vi $ \mathbf{r}'(t) = (\cos\theta,\sin\theta) $ og pr. "idiotreglen" $ |\mathbf{r}'(t)| = 1 $. Så resultatet herover simplificerer til
$$ \int_\ell g(x,y)\,d\mu = \int_a^b g(\mathbf{r}(t))\,dt. $$
Lad $ \mathcal{K} $ være en kurve parameteriseret ved $ \mathbf{r}(t) = (x(t),y(t)) $, hvor $ t \in (a,b) $ og $ x(t) $ og $ y(t) $ er differentiable. Så er længden af $ \mathcal{K} $
\begin{align}
\int_\mathcal{K}\,d\mu = \int_a^b |\mathbf{r}'(t)|dt.
\end{align}
Radontransformationen
Kompakt støtte
Vi er nu klar til at takle Radontransformationen. Denne er en operator, som vi kort benævte dem i afsnittet om funktioner, mellem funktionsvektorrum. Vi vil her definere den på funktioner med kompakt støtte, men rent teknisk kunne vi tillade andre funktioner.
Lad $ f: \mathbb{R}^2 \to \mathbb{R} $. Vi siger at $ f $ har kompakt støtte, hvis der findes en radius $ R > 0 $ således at $ f(\mathbf{v}) = f(x,y) = 0 $ når $ |\mathbf{v}| \geq R $. Vi kalder $ R $ støttekonstanten.
Funktionen $ f $, hvor $ f(x,y) = 1-x^2-y^2 $ når $ |(x,y)| \leq 1 $ og $ f(x,y) = 0 $ når $ |(x,y)| > 1 $ har kompakt støtte.
Det lyder måske begrænsende at vælge vores funktioner på den måde. Men det er en rimelig fysisk antagelse, i det objekter vi ønsker at skanne med CT naturligt er begrænsede i deres størrelse.
Profilkurver
Lad $ f : \mathbb{R}^2 \to \mathbb{R} $ være en funktion med kompakt støtte og støttekonstant $ R $ og $ 0 \leq \theta < \pi $. Lad $ \ell_{\rho,\theta} $ og $ \mathbf{r}_{\theta,\rho}(t) $ være en ret linie of dens parameterfremstilling som givet i lemma 12.
Integralet af $ f $ langs $ \ell_{\rho,\theta} $ er givet ved
$$ I = \int_{\ell_{\rho,\theta}} f(x,y)\,d\mu. $$
Siden funktionen $ f $ har støttekonstant $ R $ kan vi lade $ a = -R $ og $ b = R $. Uden antagelsen om kompakt støtte havde vi haft et integrale over hele tallinien $ (-\infty, \infty) $ og det er bestemt ikke alle funktioner der integrerer til en endelig værdi over uendeligt store intervaller.
Vi observerer at værdien $ I $ må variere ved ændring af valg af $ \rho $ og $ \theta $. Fastholder vi $ \theta $ kan vi definere en funktion
\begin{equation}
p_\theta(\rho) = \int_{\ell_{\rho,\theta}}f(x,y)\,d\mu.
\end{equation}
$ p_\theta $ er på en måde den "skygge" $ f $ kaster i retningen $ \theta $. Vi kalder grafen for $ p_\theta(\rho) $ for profilkurven for $ \theta $.
Radontransformation
Radontransformationen er essentielt set ikke andet end samlingen af alle profilkurver.
Lad $ f : \mathbb{R}^2\to\mathbb{R} $ være en funktion med kompakt støtte og støttekonstant $ R $. Radontransformationen er operatoren $ \mathcal{R} $ er givet ved
\begin{equation}
\begin{aligned}
r(\rho,\theta) &= (\mathcal{R}f)(\rho,\theta) = \int_{\ell_{\rho,\theta}} f(x,y)\,d\mu \\
&= \int_{-R}^R f(\rho\cos\theta - t\sin\theta, \rho\sin\theta + t\cos\theta)\,dt
\end{aligned}
\end{equation}
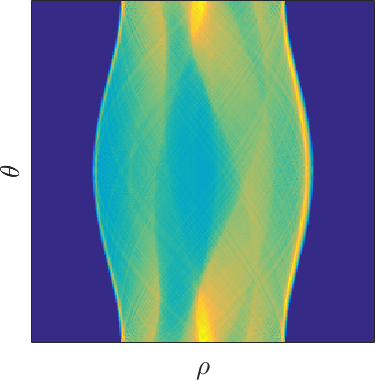
Vi kalder $ r(\rho,\theta) $ for sinogrammet.
Ofte vil vi benytte $ R = \infty $ i formlen, hvilket ikke ændrer noget af betydning, siden $ f(x,y) = 0 $ når $ |(x,y)| > R $.
Resultatet af Radontransformationen kaldes ofte et sinogram efter de sinusoidiske mønstre, der dannes.
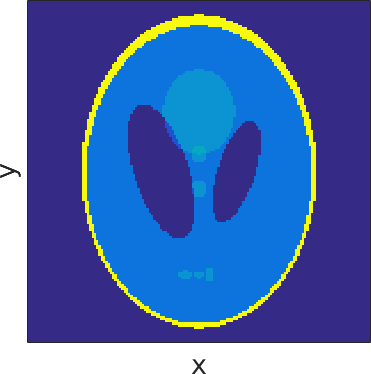
Shepp-Logan fantomet. Ofte brugt test-billede til rekonstruktionsproblemer.
Sinogram af Shepp-Logan fantomet.
En alternativ formulering af Radontransformationen kan opskrives ved at bruge delta-funktionen, $ \delta(x) $.
\begin{align} \label{eq:rt-delta-form}
r(\rho,\theta) = \iint_{-\infty}^\infty f(x,y)\delta(x\cos\theta + y\sin\theta - \rho)\,dx\,dy.
\end{align}
Rent teknisk er $ \delta(x) $ ikke en funktion, men derimod en distribution, men det er meget teknisk og ikke noget vi vil komme ind på. Man kan tænke på $ \delta $ som en funktion der er $ 0 $ overalt undtagen i $ x = 0 $, hvor den er uendelig stor, på en sådan måde at $ \int_{-\infty}^\infty \delta(x)\,dx = 1 $. Specielt opsamler den funktionsværdien i punktet $ x = 0 $, så $ \int_{-\infty}^\infty f(x)\delta(x)\,dx = f(0) $.
I \eqref{eq:rt-delta-form} gør $ \delta $-funktionen, at der udelukkende opsamles bidrag til integralet langs linien der opfylder ligningen $ y\cos\theta - x\sin\theta - \rho $.
Følgende lemma kan vises ved hjælp af ligning \eqref{eq:rt-delta-form}.
Hvis $ g $ er en translation af $ f $, i.e. $ g(x,y) = f(x-x_0,y-y_0) $, og $ r_g $ or $ r_f $ er Radontransformationen for hhv. $ g $ og $ f $. Da er
$$ r_g(\rho,\theta) = r_f(\rho - x_0\cos\theta - y_0\sin\theta, \theta). $$
Rekonstruktion
Rekonstruktion er det helt store problem inden for tomografi. Alt op til nu har handlet om at kunne formulere Radontransformationen der er forward modellen. Forward modellen producerer de data (sinogrammet) der måles i den virkelige verden, såfremt objektet (funktionen) allerede er kendt. Men objektet er ikke kendt, hvorfor der tys til tomografi. Så hvordan rekonstruerer man objektet?
Backprojection
Backprojection er den naive rekonstruktion og går essentielt ud på at for hver vinkel $ \theta $ tvære profilkurven $ p_\theta(\rho) $ ud over området, hvor funktionen skal findes. Man kan formulere det som et integrale.
Lad $ r(\rho,\theta) $ være et sinogram, da er backprojection af $ r $ defineret som
\begin{equation}
f_b(x,y) = (\mathcal{B}r)(x,y) = \int_0^\pi r(x\cos\theta + y\sin\theta,\theta)\,d\theta.
\end{equation}
Backprojektion har dog nogle problemer. Specielt er den ikke særlig skarp, hvilket har den forklaring at $ f_b $ er den rigtige løsning $ f $, men foldet med en slørende kerne[4].
Lad $ f: \mathbb{R}^2\to\mathbb{R} $ være en funktion med kompakt støtte og lad $ r(\rho,\theta) $ være Radontransformationen af $ f(x,y) $. Hvis $ f_b $ er backprojection af $ r $, gælder det at
$$ f_b(x,y) = (h \ast f)(x,y) = \iint_{-\infty}^\infty h(s,t)f(x-s,y-t)\,ds\,dt, $$
hvor $ h(x,y) = |(x,y)|^{-1} $.
Observer først, at hvis $ g(x,y) = f(x-x_0,y-y_0) $ og med Radontransformationer hhv. $ r_g $ og $ r_f $, da
\begin{align*}
f_b(x-x_0,y-y_0) &= \int_0^\pi r_f(x\cos\theta + y\sin\theta - x_0\cos\theta - y_0\sin\theta,\theta)\,d\theta \\
&= \int_0^\pi r_g(x\cos\theta + y\sin\theta,\theta)\,d\theta = g_b(x,y).
\end{align*}
Dette betyder at backprojection virker ens overalt. Ergo, er det nok at undersøge effekten i et enkelt punkt, fx $ (0,0) $. Dermed, vha. substitutionen $ t = -r $ fra linie 1 til linie 2,
\begin{align*}
f_b(0,0) &= \int_0^\pi r_f(0,\theta)\,d\theta = \int_0^\pi \int_{-\infty}^\infty f(t\cos\theta, t\sin\theta)\,dt\,d\theta \\
&= \int_0^\pi\int_{-\infty}^\infty \frac{1}{|r|}f(0-r\cos\theta,0-r\sin\theta)|r|\,dr\,d\theta \\
&= \iint_{-\infty}^\infty \frac{1}{|(x,y)|}f(0-x,0-y)\,dx\,dy = (h\ast f)(0,0).
\end{align*}
Fra linie 2 til linie 3 bruges et skift fra polære til rektangulære koordinater, $ x = r\cos\theta $ og $ y = r\sin\theta $ og $ dx\,dy = r\,dr\,d\theta $.
Filtered back projection
En mere avanceret metode end back projection er filtered back projection. Denne giver langt skarpere billeder end back projection, og er faktisk en invers Radontransformation. Den gør brug af Fouriertransformationen til at arbejde i frekvensdomænet, hvor den forstærker høje frekvenser, hvilket blandt andet giver skarpere kanter.
Lad $ r(\rho,\theta) $ være et sinogram, da er filtered back projection af $ r $ defineret ved
\begin{equation}
\begin{aligned}
f(x,y) &= (\mathcal{FB}r)(x,y) \\
&= \frac{1}{4\pi^2}\iiint r(\rho,\theta)e^{i\omega(x\cos\theta + y\sin\theta - \rho)}\omega\,d\rho\,d\omega\,d\theta,
\end{aligned}
\end{equation}
hvor $ \omega $ og $ \rho $ integreres over hele $ (-\infty,\infty) $ og $ \theta $ integreres over $ (0,\pi) $.
$ i $ er her den imaginære enhed, der opfylder at $ i^2 = -1 $.
Lineær Algebra
Lineær algebra handler i princippet bare om at løse ligningsystemer med $ n $ ligninger og $ m $ ubekendte. For små værdier af $ m $ og $ n $ er vi ret gode til det, men for store værdier kan det blive en kompliceret afære. Det vil være en stor fordel, hvis man har noget erfaring med programmering, hvis man vil prøve det følgende af selv.
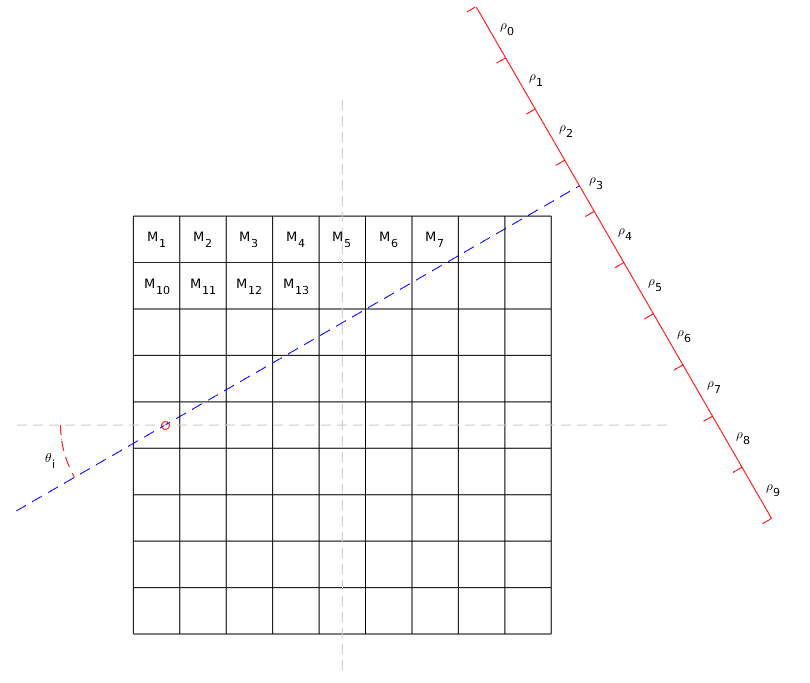
Første trin på vejen er at diskretisere Radontransformationen. Det gør vi på følgende måde: Vi antager at vores objekt er nogenlunde ensartet, så funktionen, der beskriver det, kan anses som konstant på et grid $ M $.
Vælg et $ m\times m $ grid, $ M $, hvor objektet findes. Lad $ M_j $ være det $ j $'te grid-element.
Vælg værdier $ \rho_0,\rho_1,\dots,\rho_d $ svarerende til detektor-positioner i en skanner.
Vælg vinkler $ \theta_0,\theta_1,\dots,\theta_n $, som der måles fra.
Lad $ (\rho,\theta)_k $, $ k = 1,\dots,d\cdot n $, repræsentere alle kombinationer $ (\rho_i,\theta_j) $.
Beregn for hvert grid-element $ M_j $ længden af liniestykket af linien beskrevet ved parret $ (\rho,\theta)_i $, der går gennem $ M_j $. Hvis linien ikke går igennem $ M_j $ sættes værdien til $0$. Kald denne værdi $ a_{i,j} $.
Eksempel på distretiseringssetup.
Hvis $ x_j $ er funktionsværdien på elementet $ M_j $, har vi følgende ligninger
\begin{align*}
\sum_{j=1}^{m^2} a_{i,j}x_j = b_i
\end{align*}
for alle $ i = 1,\dots, d\cdot n $. $ b_i $ er de målte data svarende til skanningen langs $ (\rho,\theta)_i $. Dette kan skrives kort som $ A\mathbf{x} = \mathbf{b} $, hvor $ \mathbf{x} = (x_1,\dots,x_{m^2}) $ og $ \mathbf{b} = (b_1,\dots,b_{d\cdot n}) $ er vektorer og $ A $ er en matrix,
\begin{align*}
A = \begin{bmatrix}
a_{1,1} & a_{1,2} & \cdots & a_{1,m^2} \\
a_{2,1} & a_{2,2} & \cdots & a_{2,m^2} \\
\vdots & \vdots & \ddots & \vdots \\
a_{d\cdot n,1} & a_{d\cdot n,2} & \cdots & a_{d\cdot n,m^2}
\end{bmatrix}.
\end{align*}
Rekonstruktionsprocessen er nu den, hvor $ \mathbf{b} $ er kendt og $ \mathbf{x} $ er ukendt. Der er mange måder at gå til et problem som $ A\mathbf{x} = \mathbf{b} $. Har man først $ A $ og $ \mathbf{b} $ i et program som MATLAB eller Octave, kan man benytte sig af de indbyggede funktioner og få mindste kvadrater-løsningen $ \mathbf{x}_\text{LSQ} $ med blackslash kommandoen x = A\b eller en lineær løser som x = linsolve(A,b). Alternativt findes der iterative metoder, som fx Kaczmarz' metode, se mere i [21].
Litteratur
How math can save your life: Tomography - Chris Budd and Cathryn Mitchell